22nd March 2018
This article will help you get to grips with the basics of the Altum Platform and will guide you step-by-step to creating, training and running your first deep learning model.
To give a consistent frame of reference, when we refer to deep learning models, we are referring to a neural network with several or more hidden layers. These artificial neural network models are representative of the workings of the neurons and connections in the human brain and have, in the last few years, become a key driver for intelligent applications that you interact with every day; from detecting faces in photos, to predicting what movies you might interested in on Netflix, the workings behind these algorithms are deep neural networks taking in features and outputting a classification or prediction.
If this is your first time learning about neural networks, we strongly suggest reading through some introductory material before continuing, as this intro assumes at least basic conceptual knowledge of neural networks, their applications, data features and model training.
Andrew Ng Course in Machine Learning
Making a Simple Neural Network
The dataset is often overlooked by users who are excited to get started with making an AI model to predict something new and ground-breaking. In reality, the dataset is the single most important factor in the success of your model. Aside from asking the question "is my dataset representative of what I want to achieve" (e.g. if you are trying to make a model to detect the faces of people, having a dataset of 50 photos of a crowd of people at different angles will probably not achieve your desired outcome) you should also have the dataset clean, valid and in a format that your model can accept.
For this introduction article we will make this step simple by using a well-known and widely used dataset called Iris. The Iris dataset contains 150 data rows, each with 4 attributes (or features) about 3 types of flowers: Iris Setosa, Iris Versicolour and Iris Virginica. These 3 flowers will be our prediction categories, and we will be trying to build a model that will learn the characteristics of each flower type, based on its 4 features from the 150 labelled data points. The 4 features of the dataset are the: Sepal Length, Sepal Width, Petal Length and Petal Width.
In the end we will be able to pass our trained model an "unknown" data row of the 4 features, and our model will be able to give a probability value to each category it thinks that our data represents (e.g. our model could produce the output [0.97, 0.01, 0.02] for the categories [Setosa, Versicolour, Virginica] indicating that there's a 97% probability that the data you have presented the model is of the flower-type Setosa and a 1% and 2% probability it is for the other two categories respectively).
Let's begin!
As discussed above we will make use of the Iris dataset for this tutorial. However the Altum platform accepts any dataset you choose to represent. To upload a dataset to the platform, it has to meet certain conditions:
What this means for our Iris dataset is that the first row should have the headings:
Sepal Length, Sepal Width, Petal Length, Petal Width, y_Setosa, y_Versicolour, y_Virginica
The subsequent rows should contain the data corresponding to those headings; with the first 4 columns representing the features that our model will learn on, and the last 3 columns being a binary representation of the categories we wish to classify each row into. E.g.:
5.6, 2.5, 3.9, 1.1, 0, 1, 0
We have already prepared a training file for this tutorial which you can download below:
You may notice we mentioned the Iris dataset contains 150 rows of data, but our training file only has 147. This is because, for this example, we have extracted 1 row from each category at random to serve as a test dataset for later on to run our model on data which it has never seen before.
Once you have downloaded the training file (or created your own) navigate to the "Data Manager" tab in the Altum Platform and click "Upload Dataset" to upload the CSV file containing your training data.
The next step is creating the deep learning model which will be the brains of this process. Usually this would be a tedious process of coding complicated linear algebra operations to be able to create even a simple model flow. Luckily the Altum Platform has a visual GUI model builder which requires no coding at all.
Navigate to the "Model Manager" tab then go ahead and click on the "Create New Model" button.
This will create a default model of your naming. After the model is created, select it from the left hand list to open it in the visual editor. The default model is a simple, single hidden layer network. In the editor you can choose to edit the names of the hidden layers, add/remove hidden layers (a minimum of 1 hidden layer is required at all times), control the layer type, activation function of the layer as well as the number of neurons in that layer.
For this example we suggest adding an extra hidden layer to make a total of two hidden layers, making them both fully connected, with 20 neurons each, and setting the activation functions to TanH for the hidden layers, and Softmax for the output layer. The input layer dimensions should match your dataset dimensions (features) which in this case is 4. The output layer neurons should match the dimensions of your output layer which in this case is 3.
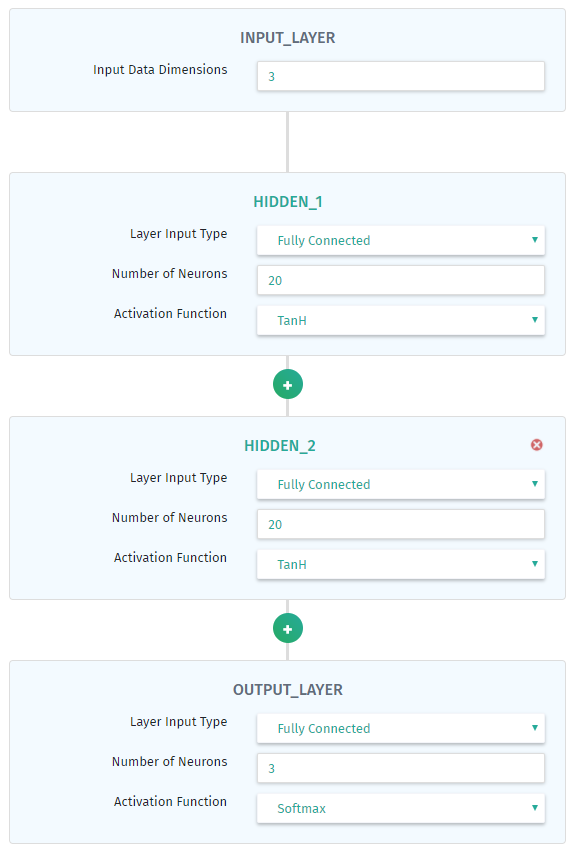
When you have created a model you are happy with click "Save Model" to save it. You can also upload your own custom coded models for training via the "Upload Custom Model" button. Currently the accepted format for these models are Keras models saved to a .h5 file via the Keras model.save() function.
Currently we have the dataset and the model saved in our Altum Platform. Now we need to combine the two so that our model can become intelligent and learn on the data.
From the "Model Manager" select the model you with to train and the dataset you wish to use for training. Then select your Hyperparameters from the right hand tab and click "Run Training Job" to initiate a training job on the Altum Brain.
For this particular example we recommend having the following options:
Normalise Data: Yes (this will normalise the data to values between 0 - 1 which helps the model converge)
Train/Test Split: 100% train : 0% test (usually we would set the split to 70% : 30% to leave some data for cross validation, however as we are working with a small dataset and have already removed 3 values for our own manual testing later on in Step 4, we can just train the model on the remaining 100%).
Epochs: 500 (the number of iterations to run for this training job).
Once the job is successfully submitted you can navigate to the "Jobs" tab to view its progress. Note, for small training jobs like this the initiation time of the job can far outweigh the time it takes to do the actual training. The Altum Brain has to spend some time spinning up a process for the job and performing various data normalisation and validation tasks before running the training on the job. For our example, the job can take around 5mins to complete.
Congratulations, once the job has successfully finished, as indicated in the "Jobs" tab, your model is now trained on the data. You can now download your trained model (as a Keras .h5 file) or let it run predictions on new data via the Altum Platform web interface or the API directly.
To do our test on the trained model we will use the Altum Platform web interface. The prediction module can be found on the "Dashboard" tab, so go ahead and navigate to it.
On the right hand side you will see a "Predict Data" button. Go ahead and click it to get presented with another upload window.
Remember those 3 data rows we took out of the training data for testing later on, well now we can use them to run the model on. The predictable data should be presented in a similar CSV to the upload data, but with two crucial differences:
Go ahead and download our pre-compiled testing dataset with the 3 rows from earlier below:
Now use that file (or your own data) to upload on the Predict Upload screen.
As soon as the upload is completed the model will start running through the data to make a prediction. This prediction will be displayed in a table below the Predict Data button. And, our final prediction table for the 3 rows should look like this:

You can see that for the first row the model gives a 99.98% chance that this data represents the category of Iris-Setosa. The next row shows the model making a prediction of 91.31% that this data belongs to the category of Iris-Versicolor (and an 8.68% chance that is in fact Iris-Virginica instead). And the final row gives a 99.54% prediction that the data is for Iris-Virginica. This is a perfect strong prediction for the true values of Iris-Setosa [1,0,0], Iris-Versicolor [0,1,0] and Iris-Virginica [0,0,1] for the respective data rows.
Of course, this is a simple example. The power of deep learning extends to application far more complex than simple flower predictions. This is where the Altum Platform hopes to help users making deep and complex models, by offering a variety of powerful training tiers users can train their models on the high-level, scalable machine learning architecture of Google's server farms.
We look forward to seeing the applications of the Altum Platform.